Web Design
Lesson 1: Printer-Friendly version
As with the other similar pages on this site, this page is designed to be easily printed out and read offline, away from the computer. If you are trying to follow this lesson online you will find it much more convenient to return to the full lesson 1 menu.
You can also go straight to the printer-friendly version of lesson 2 from here.
Contents
- 1.1 what is a web site?
- 1.1.1 what is a web page?
- 1.1.2 what is HTML?
- 1.1.3 what is a web site?
- 1.2 the tools you need
- 1.2.1 browsers
- 1.2.2 editors
- 1.2.3 other tools
- 1.3 naming your files
- 1.4 URLs
- 1.5 tags
- 1.5.1 what are tags?
- 1.5.2 formatting rules
- 1.5.3 nesting tags
- 1.6 attributes
- 1.7 comments
- 1.8 the head, the body and structural tags
- 1.8.1 the head and body
- 1.8.2 structural tags
- 1.9 page titles
1.1 what is a web site?
1.1.1 what is a web page?
A web page is a data file so in many ways is no different from a Word document or a spreadsheet. The various programs on your PC -- word processors, spreadsheets, video players or anything else -- are properly known as applications. Think of them as like a car, with the hardware being the ground to drive on, and the operating system (which on most PCs is Microsoft Windows) being the traffic system and rules of the road. In the case of web surfing (and web design), the applications are web browsers. You are using one right now to look at this page and I talk about them a bit more in 1.2 below.

But even the smartest car cannot run without fuel. When you work with a word processor, the application does nothing on its own. You also need a data file, in other words, the actual document you are writing or editing. Files are those things named something.doc (in Word), something.xls (in Excel) or something.html when reading or writing a web page. So at the simplest level, a web page is a data file with the extension .html. And like any other data file it can be edited, moved around between folders, renamed and so on. We saw that in the lecture.
When you're browsing a web page, therefore, you're not receiving a signal as if you were watching TV. You are simply opening a data file, just as if you were reading a Word document. Now, of course, when browsing the World Wide Web, as the name suggests, the HTML file you're opening could actually be located anywhere in the world. To make a browser find a file remotely, you type in the web page's address into the location bar: known as the Uniform Resource Locator, or URL. The URL of this page is:
http://www.leeds.ac.uk/acom/webdesign/materials/lesson1print.html
Typing something like this into the browser's location bar and pressing return instructs your computer to access a distant computer, known as a server, and to download the HTML file via the telephone line. But you can also't create your own HTML files on your own computer and access them locally. More information on how to do this is given in 1.2 below which discusses the tools you need.
 |
"I sometimes see web pages which end in extensions other than .html, like .htm, .asp, .cfm or .cgi."
The reason for .htm is that older versions of Windows insisted on a maximum of three characters for extensions. This restriction has been removed. It actually doesn't matter which one you use, but .html is favoured. Whichever one you choose, though, be consistent as a computer won't think to look for mypage.html if you wrongly told it to look for mypage.htm.
If you see any other extensions what you are looking at is still a web page, but it is not written in HTML. This is usually because it uses more advanced technologies. We will touch on these in the more advanced parts of the course but for now they are best left to one side. At this point you should be calling all your web pages something.html.
|
1.1.2 what is HTML?
When you look at a web page online you are not actually seeing it in its proper form. To see what an HTML file really looks like, click on the right-hand mouse button anywhere on this page (except over an image). Then choose the option, "View Source". (If you are reading this page in Opera, press Ctrl+F3 instead.) That's an HTML file. (Remember that "View Source" routine - it's an important way to see what is going on on any web page, and you can use it to check the structure of not only the pages on this site, but pretty much any page on the web.)
HTML files are plain text. They contain only unadorned text and a few symbols, made up of the basic 255 ASCII characters (ASCII is the standard code for translating the binary digits computers use into basic text). They can't contain images, colours, or even simple formatting such as italics.
The term HTML stands for:
HyperText Markup Language.
The "language" part of the term is rather misleading. It makes it sound as if web design involves a long and difficult process, as is learning another human language (or a programming language). But it's much easier than that. Once you've learnt a few basic techniques, writing a basic web page is simple; no harder than writing a letter or essay.
"Hypertext" is the technical term for the way you can jump from one part of a passage of text to another, or to a different passage altogether. That is discussed in this web site's accompanying book (chapter 3), although you will see more of it in lesson 3.
The most important part of the term HTML is the M, for "markup". HTML is a way of "marking" plain text at the places you want the browser to apply some special formatting. Remember that in the lecture we used the example of punctuation to show how this is actually a fairly commonplace idea. When you want to point out to the reader that a passage of text is a quotation, "you enclose it in quotation marks like this". We don't use that many different punctuation marks, but computers are not intelligent beings (honestly) and they need information about every piece of formatting that you want to put onto a web page. When you want to tell a computer that, say, some plain text is meant to be bold text, you have to enclose the words in tags.
All formatting, or marking up, on a page is done with tags (discussed in 1.5) and associated attributes (1.6). Read those two sections for more details. If you understand them, you understand HTML and therefore web design! Of course it's not quite as simple as that - there are many different tags, and many ways of using them creatively and well - but tags are really all there is to it.
Why is it done this way? Why not just create files with pictures and colours and so on intact, and bypass the interpreting of a simpler version of the file? The answer is speed. A web page is usually read from one end of a telephone line and this means that the smaller the page is in memory terms, the better. Keeping web pages as plain text ensures that pages can be quickly transmitted and loaded; better for the reader, and indeed better for computer and telephone networks, which are like motorways, in that they are more pleasant to use and require less maintenance when traffic flows are light. It's true that more and more people have broadband access these days, but keeping things small is still an important part of writing a good site. More on this in lesson 6 and in chapter 5 of the course booklet.
1.1.3 what is a web site?
A web site, then, is a collection of web pages, or several HTML files. A site will usually (but not always) have a coherent theme, and probably a consistent visual style. But in the end the thing that defines a site is that all the files are stored in one place. You'll see that whenever you move around this site, the web address stays the same, always beginning http://www.leeds.ac.uk/acom/webdesign/....
For more information on how that URL was put together, see the section on URLs (1.4), but bear in mind for now that one reason it works is that the HTML files which make up this site are all stored in the same folder. This is a good habit to get into, although when your sites start getting very large you may start using subfolders as well (see 3.4).
Also bear in mind that a "web site" does not just include HTML files. Most web sites will also incorporate graphic images, and these are also stored in the folder alongside the HTML files. Also, there's a special kind of file called a style sheet, which contains information about the appearance (or style) of the site, and which we will look at in lesson 2.
1.2 the tools you need
1.2.1 browsers
First, you need a web browser. If you don't have one you won't be able to see how your site will look to others. Of course most PCs these days come complete with Microsoft's Internet Explorer (IE), and this is the browser installed on the university system.
But this is not the only browser available. Until about 1998 the dominant web browser was Netscape, which has since changed its name and become Mozilla. ACOM students can access a copy from Departmental Software (if you are unsure about this see a demonstrator).
Another good one is Opera, which you can download for free from http://www.opera.com/download/. There's also Lynx, which is a text-only browser and can be downloaded from http://lynx.browser.org/.
The differences are minimal between browsers in terms of the way they render pages as long as the HTML is correct. However they differ greatly in terms of the assistance they offer designers. IE offers almost no assistance at all. Opera offers some, and Mozilla offers a lot of very helpful facilities. At the moment it would not help you much to explain what this help is as a lot of it is to do with things you have not yet seen. But I will come back to it in lecture 6.
If you're new to computers, or unsure about them, this may already be making your head spin. If so, don't worry about it. For now, just use IE. But anyone intending to take web design seriously needs to look at their pages in as many browsers as possible, so the more you have installed on your computer the better. The reasons for this are covered in lesson 6, so we will leave the issue until then.
1.2.2 editors
As an HTML file is plain text you do not need any fancy applications to create it. All you need to use is Notepad, the simplest of all text editors. On the university system, you can access it through the Start menu (button in the bottom left corner of the screen) - Programs - Utilities - Notepad. Start it up, type in your structural tags, choose a name for your file, and off you go!
There are some other web-page authoring tools available. You may have heard of (or already used) HTML generators like Microsoft's Front Page or Macromedia's Dreamweaver (which is also available on the university system). Many web design courses will teach you how to use these packages, but this is not one of them. Generators like this create web pages at one remove. They don't bypass the need to create a plain text file in the HTML format; instead, they create this file for you. But to use tools like this properly, you need to know how HTML works, and what it can and cannot do. That's why this course focuses on the underlying techniques rather than, as many other web design courses do, just teaching you the use of the editors. By the time you reach the end of this course you will know enough about HTML to be able to make your own decision about whether to use Dreamweaver or not.
In the end it doesn't matter how you write your HTML file, the basic principle remains. When creating a web page, you are able to have two applications looking at the same data file (the HTML file) simultaneously. You are getting two different "perspectives" on the file, if you like. We saw that in the lecture. Editors create the web page and browsers interpret and display it.
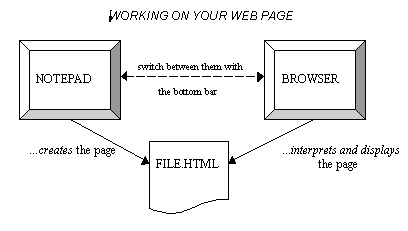
To open a page in a browser, see the diagram below. This is taken from Netscape but the process is very similar in IE or any other browser. When you follow this menu option you will open a "browse" window, as for any other application, by which you can pinpoint your own HTML file on your local drives (e.g. your M: drive, which is your university user space, or possibly your C: drive, if you are working on your home PC).
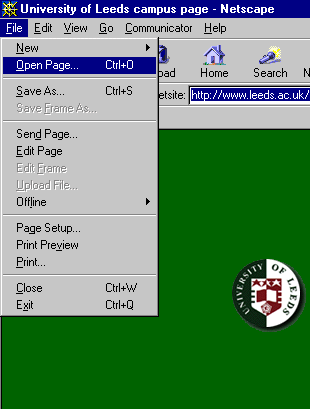
After you've made your changes to a page in Notepad, remember to save them! (It's easy to forget!) Then return to the browser window and press Refresh (or on some browsers, Reload). This tells the browser to go and get the latest version of the page. Your changes should then be shown in the browser window. And once you've seen what they look like you go back to the editor again and keep going until you're happy!
 |
WARNING! Make sure you don't use the "Save" or "Save As.." options in a browser to save a web page. You can see above that Netscape allows you to do this: so does IE. If you do this you will cause some strange things to happen, which can be frustrating even for someone familiar with web design - the main thing that'll happen is that your links will stop working if and when you publish the site. For beginners at web design the results can be perplexing - worse, the problems may even go unnoticed. So the basic rule is as follows: only ever save a page from within Notepad, not from within the browser window. SAVE IN NOTEPAD: OPEN IN THE BROWSER. |
1.2.3 other tools
For those of you that just want to create simple sites with the minimum of hassle, a browser and Notepad are really all you need. However there are other applications which will be useful.
A very good tool I use is Alentum Software's HTML Search and Replace which acts like a combined browser/editor. This alone is helpful but the application also contains the extremely useful feature of allowing search-and-replace changes to all files in a folder simultaneously. If and when you write large sites you will quickly realise what a bonus this can be!
Those more into the graphical side of web design will also need a good picture editor. The state-of-the-art packages are Adobe's Photoshop and Illustrator, but there are many other useful ones, including Jasc Software's Paint Shop Pro, which has the advantage of being the one on the university system.
That'll do for now: maybe you know of more applications. But I'll say again that all you really need for all this is a web browser and Notepad. Of all the things that you can do with a computer, web design is probably the thing which has the best potential results for the minimum of financial outlay and technical skill. And that's why I think it's a very useful thing to learn. So let's cut to the chase and get on with it.
1.3 naming your files
To a large extent you can save your web pages under whatever name you like. But there are some restrictions, so this page runs through what they are. Though this seems a trivial issue, not remembering these rules is a common reason why web sites do not work, particularly with beginners. Remember also that a web site comprises not only HTML files, but also images, style sheets and possibly even video or audio files. These rules apply to all file types.
First of all, of course, you have to follow the standard naming convention which is:
filename.ext
ext is the extension of the file type you're saving. For HTML files it is .htm or .html. For other file types the extension will depend on the file, but by the time you're dealing with these kinds of files you'll know what extensions will apply.
|
WARNING! Notepad will default (in other words, automatically assume) you want to save files with the .txt extension. .txt and .html are essentially the same, but browsers do not fully understand pages which are called something.txt. Make sure you always type the full filename when saving things in Notepad: e.g. index.html, not just index. If you type only "index" your file will be saved as index.txt which cannot be used on the WWW. Also note that Notepad expects you to load .txt files as well, so when looking for a file, change the "Save as type" box to "All Files". You get used to this pretty quickly, but it can confuse beginners. |
filename is your choice, but you are best limiting it to something under about 20 characters. The name of an HTML file is usually (though not always) shown at the end of the URL, which will appear in the browser's location bar. Therefore, you can see that the file you're looking at at the moment is called lesson1print.html. If you followed the virtual lecture for this lesson, you should already have named and created a file called firstpage.html.
There is one special name you should be aware of. That is index.html. Your site's front page - the page which visitors see first - should be given this name. There are two good reasons for this. The first is that it means you get a better-looking URL. You may notice that a lot of URLs - like http://www.leeds.ac.uk/ - don't have a filename visible at the end. If a browser gets given a URL which does not end in a filename it will assume it is looking for a file called index.html. (You can actually change this, but it's a very advanced issue and not worth worrying about now.) In other words, that URL is effectively the same as http://www.leeds.ac.uk/index.html. The second reason is connected to this. If you don't have an index.html file and someone comes looking for it, they will in fact see a listing of all the files on your site. This is a mild security risk, but it also looks very sloppy. So an early habit to get into is to always name your front page index.html.
You should definitely avoid spaces in the filename (that is, first page.html). The underscore (_) character is the usual "replacement" for a space, if for whatever reason, you want to have a two-part filename. Honestly, don't use spaces, though it seems such a trivial thing (and you do sometimes see them used online). Browsers don't like them, often replacing them with other characters. Had I used a space in the name of this file, the URL might have become http://www.leeds.ac.uk/acom/webdesign/lesson1%20print.html. It doesn't necessarily make it harder for browsers to find the file but you may want to publish the URL of your site and that's obviously more difficult to type. It looks ugly too. All in all, it makes sites less robust. Also don't use characters other than the underscore or the hyphen (-) if you can help it: definitely avoid characters like %, ?, #, which have other special uses in Windows.
You will need to refer back to these filenames when you use internal links, which we will come to in lesson 3. When we do this you will see that the full file name - or what is known as the path name - of a file may also include references to folders. While we're still only dealing with single web pages, though, that is not an issue so we will not worry about it until then.
1.4 URLs
URL is an abbreviation for Universal Resource Locator. It is the "address" of a web page, and usually looks something like this (this being the URL of the page you're looking at right now):
http://www.leeds.ac.uk/acom/webdesign/materials/lesson1print.html
It's worth "deconstructing" this seemingly random collection of characters. As you will eventually be publishing your web site "for real", you'll need to know not only what your site's URL is but why it is what it is. This topic is covered in more detail in chapter 6 of the printed course booklet, where I also discuss the ways you can get a more "user-friendly" and/or memorable URL, and how to market and distribute your URL. However, some brief points are worth making here. Even if this page leaves you a little befuddled it is very worth your while to read 1.4.1 below, which discusses the WWW directory and how you can use this to publish pages on the Web very easily. (However this is not relevant to readers who are not students at Leeds University.)
http://: This abbreviation stands for "HyperText Transfer Protocol". Technically it's still possible to see other prefixes here like "ftp://" but this is very rare and when you do, in any case, you are no longer strictly "on the WWW" (although you're still on the Internet). Although this is near-universal, the prefix is still part of the URL. In web browsing you can sometimes do without it, but web designers always need to remember that it is there.
www.leeds.ac.uk: This is the domain name. It represents a particular server on which the web page can be found; more simply, it is the name of the computer on which the HTML file is stored. In this case, the server is obviously that of Leeds University.
/acom/webdesign/materials/: Sometimes, a domain name is all you need. But larger sites are usually split into sections, using folders. What we have here are two further "levels" of the main http://www.leeds.ac.uk/ site:
http://www.leeds.ac.uk/acom/ is a sub-site of the main Leeds University site...
http://www.leeds.ac.uk/acom/webdesign/ is a sub-site of the ACOM site...
http://www.leeds.ac.uk/acom/webdesign/materials/ is a sub-site of the Web Design site.
When you publish your site you can set folders like this up on the server. If you want some practice at this, keep reading.
subj_url.html: The final part of the URL is, simply, the name of the HTML file. That is why it always ends in .html (or .htm). However, remember what was said above (1.3) about the index.html file. All front pages should be given this name, as it precludes the need for a filename at the end of the URL, which makes it easier to remember.
If you're still confused, think about how similar this is to "real-world" addresses. These are made up of various parts which help specify an address with increasing precision, although when writing out addresses, we tend to write them with the more specific bits first: in other words we may go "house number - street name - district - town or city - county". (The postcode is an exception, but don't worry about that - it's just an analogy.) With web addresses it's the other way round, but the general principle is the same: the domain name is the general area of the page, and subfolders and file names then pinpoint it precisely.
1.4.1 The WWW directory
|
WARNING! This section is only relevant to students at Leeds University. If you happen to be following this site but are not a student here at Leeds, you will not be able to use the facility I'm going to describe. However, the last paragraph on subfolders and path names might help clarify some of the information above. |
ISS, The nice people who run the computer network at Leeds Uni, have made it easy for you to publish pages on the Web for real. What you need to do is create a folder on your M: drive called WWW. WWW must be in capital or upper case letters for this to work. If you save your web pages in this folder they will get the following URL:
http://www.personal.leeds.ac.uk/~[your username]/[the filename.ext]
For example, if a student with the username dep2abc saves a file called myfile.html in their www directory, the URL of that file would be:
http://www.personal.leeds.ac.uk/~dep2abc/myfile.html
Do note the tilde (~) - the wiggle that the Spanish sometimes put on top of their Ns - this is a necessary part of the URL in this case. It can usually be found on the extreme right of the middle row of the keyboard, above the hashmark (#), which also has application in HTML. Note also that if you have an index.html file in this directory, you won't need the final filename; your URL will end after "dep2abc/" (or whatever your username is).
The lecture started you off with the use of this folder, so hopefully by now you have begun to use it at a basic level. Let's create a subfolder within this folder, however. Repeat what you did in the lecture, only now one level further down: instead of creating "www" on the top level of your M: drive, go into "www" and create another folder, called "sub". Now, if you had saved myfile.html within "sub", its URL would be (and compare this to the one just above):
http://www.personal.leeds.ac.uk/~dep2abc/sub/myfile.html
You may never use subfolders, particularly if you're only writing small sites. But it helps to know that they are there, and they are an important element in why URLs look like they do.
1.5 tags
1.5.1 what are tags?
To all intents and purposes, web sites are tags and tags are web sites. Every piece of formatting you apply to the plain text is done with a tag, or a pair of tags. Even attributes (1.6) and styles (2.1) can't exist without tags. This page lays out the general rules about tags rather than specific examples, but we will see plenty of those in subsequent lectures.
Once again, remember how in the lecture we used the example of punctuation as an everyday instance of markup. For quotations, we place "marks at the beginning and end of the passage, like this". So it is with tags. For instance, there is a tag which can change plain text into bold text. Have a look at the code which produced that last sentence:
For instance, there is a tag which can change plain text
into <b>bold text</b>.
You can see how the interpreted page - what you're looking at now - does not show the tags themselves, but does show their effects. To reinforce the point here is some more code, showing how I've just used another common tag, the <i> tag:
You can see how the <i>interpreted</i> page...
1.5.2 formatting rules
Web design is a pretty precise skill. You usually have to do things in exactly the right way to make them work. So it is with tags. You can't enclose tags in square brackets [ ], parentheses ( ) or anything else: only angle brackets < > will do. (Actually, they're the mathematical "less than" and "greater than" signs and usually appear above the full stop and comma on the bottom row of the keyboard.)
The general format of tags is as follows:
<tagname [attributes...]>Text to be formatted by the tag</tagname>
We'll come to attributes later (1.6). What is important here is that you understand, first, the importance of opening and then closing the tag. If you forget to close a tag the formatting will "leak out" into other text and make your page look strange. Sometimes this can lead to chunks of text not appearing on your page at all. Closing a tag is done by repeating the tag name but with that forward slash / beforehand.
Note one of two common problems here. The first is to forget one of the < >. Sometimes you see things like B>this</B> on web pages - an opening < has been left off by mistake. The other is to forget to include the / in the closing tag, meaning that the browser will just count it as another opening tag and the formatting will, once again, leak out.
|
Do tags always have to be in lower case? I've seen a lot of web pages which use UPPER CASE in the tags.
Good point. It depends on the version of HTML you are using. Up until summer 2004, in fact, this course taught HTML 4.01 (and the site was written to that standard) and in that, it didn't matter whether tags were in UPPER CASE or lower case. You could even mix them in a pair (e.g. <b>Bold text</B>). But XHTML 1.0, which is more up-to-date, insists on lower case for all tags. Maybe someone flipped a coin one day at the WWW Consortium (the people who set the rules for web design) and it came up tails rather than heads. Whatever - that's the way it is now. |
Not all tags need a closing tag. The exceptions are those which do not format text but place an "object" on a page, like an image. I will point out these exceptions when they arise.
You might also be wondering just how it is the browser "knows" to, for instance, turn links blue and underline them, as on this page (and again, refer to the code reproduced above). The answer there lies in the concept of styles, and we will discuss it in lecture 2.
1.5.3 nesting tags
Web design would be rather limited if you could only apply one tag at once. Actually you can apply any number of tags to a particular bit of text. The technical term for doubling up (or trebling, or whatever) tags is nesting. The following text, for instance, is both bold and italic, and has been produced by the following code:
The following text, for instance, is <i><b>both bold and
italic</b><i>, and has been produced by the following code:
If you do this, remember to close the tags in the opposite order than they were opened. That's why it's called "nesting". Here, the <b> tag is "nested" within the <i> tag. They do not overlap. It's always the case that the last tag you opened is first to be closed.
This is a simple case, but nesting is used in more complex ways than this. All of the examples shown so far have themselves been nested within another tag we've not met yet, the paragraph or <p> tag. And all page content is effectively nested within <body> tags. Some other tags, such as table tags, exhibit complex nesting structures. Those can be left for now. When we start working with actual tags in lecture 2 this should become clear.
1.6 attributes
Attributes qualify the formatting applied with tags. Not all tags need this, though. The tags we saw on the last page, the <b> and <i> tags, never need attributes. They apply bold or italic formatting respectively, and that's it.
However, in the case of another text formatting tag - link tags - the tag name alone is not enough. Links are produced with <a> tags. These change the appearance of text, as you can see in the earlier sentence, but they also turn that text into a link to another HTML page. In order to work, we need to tell the browser which page it actually points to. This is what I mean about qualifying the information - every link points somewhere different so clearly here the tag name is not enough. The "extra" information is enclosed inside the opening tag through using an attribute called href. (This stands for "hypertext reference". Don't worry about the details of using links at the moment: all of this will come in lecture 3.) The code for that first sentence looks like this:
in the case of another text formatting tag - <a href="lesson3.html">link tags</a> - the tag name alone is not enough.
You do not need to put attributes in the closing tag. That always contains just the tag name.
All attributes take some kind of value. In the case of href, the value is "lesson3.html". Values are always separated from the attribute by an equals sign = (note: don't put spaces on either side of the =) and are always enclosed in quotation marks " ". Again, remember we're only talking here about general rules. All the actual attributes and values which can be used on web pages will be discussed when they come up.
Sometimes, atrributes are obligatory. In other words, a tag is never seen without a particular attribute. An example is the <img> tag, which always comes with the attribute src. The tag puts an image on the page and the browser needs to know where to find that image, which is what src does. See the example: images are covered in full in lesson 5. But sometimes attributes are optional, and are only used when you need them. The height and width attributes in the example are instances of this. alt is another obligatory attribute, though.
 | Finally note that if you use more than one attribute in a tag, they can appear in any order (though never before the tag name, and never in the closing tag). Here is an example of a tag which contains many attributes: it places the image of the tower on the page. (There is no closing tag in this case, although you should note the / character therefore appears at the end of the tag. Single tags like this are a special case in XHTML 1.0 which we will deal with when we start discussing them specifically.)
<img src="avila.jpg" height="257" width="218"
alt="Image: Avila, Spain, July 2004" />
|
All this probably seems a lot to take in at this early stage but it is not necessary for you to memorise all this information. All available tags and attributes will be introduced to you in due course. But it is worth remembering the basics at this stage, and getting into the habit of using tags and attributes as correctly as you can.
|
WARNING! It is a common mistake for beginners to type multiple tags, instead of multiple attributes in a single tag. Compare this to the example above:
WRONG:
<img src="avila.jpg">
<img height="200">
<img width="150">
<img alt="Image: Avila, Spain, July 2004">
|
It's worth pointing out that attributes are used far less in XHTML 1.0 than they were in earlier versions of HTML. Most of what was once done with attributes is now done by style sheets. Attributes are still used when extra structural information is required, however. The distinction between stylistic information and structural information is very important, and is how we will start lecture 2.
On this site I use bold text to refer to tags and attributes (and style sheet properties, when we get to them). Tag names are always enclosed in angle brackets: <body>, <table>. Attributes are shown without brackets: href, alt.
1.7 comments
These are completely optional and make no difference to how your web page works. But there are reasons why you may want to put comments or notes in your HTML. Perhaps you are writing the page for an organisation, or society, and know that in the future, other people might have to maintain or update the site. Perhaps you want to leave a note or two for yourself as a reminder that you've not quite finished a particular section, or that you need to come back to it in a couple of weeks when you've worked something out. Sometimes people "comment out" actual tags because they are not needed yet.
What it basically means is that anything inbetween comment tags is completely ignored by the browser. To put a comment in the code you need an opening and closing tag, just as with everything else in HTML. The tags look like this:
<!--
Place your comment(s) here
-->
Bingo: you have a comment in the code. As ever, you need to be precise: so that's two hyphens at each end, always, not one, or three.
Comments do have uses beyond this in some cases. When working with certain more advanced techniques, for instance, <script> tags (see lesson 8), you may need to surround the relevant HTML with comment tags, to ensure that they do not cause older browsers to foul up. Newer browsers, which can recognise the advanced tags, are programmed to ignore comment tags in these circumstances. Older browsers just see the comment and breeze past the futuristic tag, unaffected. As with every other piece of cross-browser compatibility, it's a good, indeed necessary, habit to get into.
1.8 the head, the body and structural tags
1.8.1 the head and the body
When we created that first web page in the lecture, there were a lot of complicated-looking tags involved that probably got you a little worried. The biggest problem with teaching the very basics of HTML is that though it's pretty easy to get simple content onto a page using tags, the web page as a whole has to conform to a certain structure. This structure is also created with tags, and some of them look quite daunting, even incomprehensible to a beginner. Nevertheless you can't get a web page properly up and running without them.
This page will try and explain some of what is going on. Although this seems difficult please bear in mind that a lot of the time, you can forget these tags are there. I will provide you (below) with a template which you can use to create web pages without having to type these tags in every time. But unless you know at least a little about what they do and how to use them, you may make basic web design errors which could lead to your page not being at all understandable to a browser.
A web page has two distinct parts. These are known as the head and the body. As on a human being, the two parts are of unequal size. Indeed, on most web pages the head is little more than a few lines of code at the top of the file. What the head contains is information about the page rather than the information on the page. If you look at the browser window in front of you, that space between the menu bar at the top and the status bar at the bottom is the actual web page. That's the page body. It's tempting to think of this as all there is to it, but there are some things the browser "knows" about the page which are not included in the main text. These include:
- the page title (see 1.9)
- a tag called the <link> tag, which points to the page's style sheet (don't confuse this with the <a> tag, by the way)
- information about the (human) language in which the page is written, and which version of HTML (see below for more information on these).
All of this, as I said, is done with tags, and the next section explains how.
1.8.2 Structural tags
The lecture handout contains, in part 3, a "skeleton" web page. First have a look at how the head and the body are enclosed within <head> and <body> tags respectively (the comments should help you find them). Then the whole page is included in <html> tags. All three of these tags are closed. (We'll deal with the <?xml> and <!DOCTYPE> shortly). Here are the three general rules which should never be broken:
- A web page always starts with these four tags: an <?xml>; a <!DOCTYPE>; an opening <html> tag; and an opening <head> tag.
- No other tag should ever appear between the closing </head> and opening <body> tags
- The closing </body> and </html> tags are always the last two tags on the page.
Web pages are basically structured texts, and what we're really talking about here is their most fundamental structural division of all. It's like when you're classifying people: the first and most obvious "slice" to make in the classification is between men and women. The first "slice" a browser makes in interpreting the plan text is between head and body. If you get it wrong, you can get some very strange things happening. Because of the complexity of structural tags, it's best to use a template: which is what the lecture handout provides you with. Or, you can copy and paste the following into Notepad and then it's all yours:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
" http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd ">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<meta http-equiv="Content-Language" content="en" />
<title>****The page title goes here****</title>
<link rel="stylesheet" type="text/css" href="****.css" media="screen" />
</head>
<body>
****all page content goes here****
</body>
</html>
The lines of text inbetween the asterisks are not part of the structure! Sounds facile to say it, but it's worth pointing out - I have received courseworks with a page title reading "the page title goes here" or similar...
Anyway, what does all this mean? As I've said, the complex tags are often best left alone. Basically - and this is over-simplifying things, but it will do for now - the first two lines tell the browser what version of HTML the page is written in. This template (and all the pages on this site) are written in XHTML 1.0 Transitional. A "formal" definition of this is available for the browser to go and find on the site noted (the World Wide Web Consortium's site, but this is not something you will ever need to worry about unless you get into really advanced electronic publishing. By the way, <!DOCTYPE> (and don't forget the !) is the only tag name you ever see in UPPER CASE. That's because it's not actually a tag at all, but a "declaration". Hmmm.
Every other tag bar these top two are bounded by the pair of <html> tags. Amongst the attributes you can see here is one, lang, which tells the browser the human language in which your page is written. "en" stands for English, in this case. For more information see the page on <meta> in lecture 6 - you can see two after the <head> tag. These tell the browser what character set to use on the page: some languages like Chinese, Greek, Arabic have different alphabets and the browser needs to know this. Finally the language is again specified, this time for the benefit of search engines.
The page title is discussed below and the <link> tag will be covered in lecture 2. So that's it for the web page's head; and as you can see, the page body is a "blank", ready for you to put your own web page into.
That's it for structural tags. I'm sorry that they look intimidating but hopefully once you've used the template in two or three web pages you become used to seeing them there. For most of the rest of this course we will not need to touch them.
1.9 page titles
Page titles sometimes cause confusion to beginning web designers. In web design, the page title is not something which appears in large text at the top of the main browser window, like the "Web Design" which appears to the top left of every page on this site. That is properly called a page heading (see 2.5.2 for details). As with everything else that appears in the main browser window, it is ultimately included in the <body> tag.
The page title, on the other hand, appears in the blue bar at the top of the browser window. (See the screen shot below.) As information about the page, rather than information on the page, it appears in the head of the document rather than the body (see 1.8 above). If still unsure, here's an analogy. Think about the way the title of a book describes the work as a whole, as well as just being some text which appears on the cover. For instance, we talk about The Lord of the Rings as a single thing whether we mean the book, the film, or even the separate volumes of the novel.
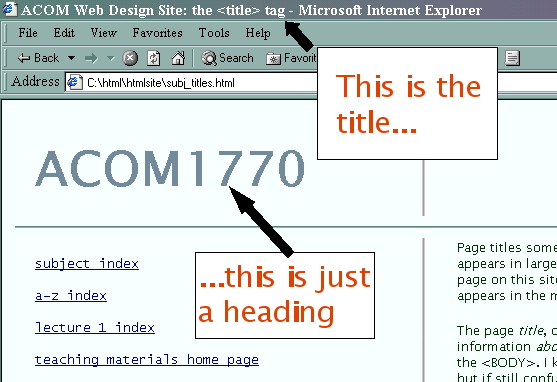
The page title is enclosed between <title> and </title> tags. There is no convention for page title text, but it should be something descriptive - and each page on your site should have a unique title. (Note that the browser will append its own name to the page title, hence the " - Microsoft Internet Explorer" at the end of the title on the screen shot (and on this page, if that's the browser you're using right now)).
A common failing of sloppy web pages is that the title is omitted, or simply made equivalent to the filename or URL. This is unhelpful to your visitors, though. Though it's officially obligatory in XHTML 1.0 to use a title, browsers will let you get away with it, but this doesn't mean you should omit a title. This will make your site more difficult to use. If you look at the buttons on the bottom bar of the screen (or use Alt+Tab to switch between windows) you will see that the page title is used in each case, showing you exactly what that particular browser window is looking at. This is very useful if you've moved off to another application, and particularly useful if you've opened multiple browser windows.
Also, as the page title is at the very top of the HTML, it will be the first thing to load, and will appear in a browser window almost immediately. If it is descriptive, it will give the user some idea of what they're downloading. This is useful both on complex sites like this one, where it might be the case that the user's followed a different link than they intended, or if the page has been found through some kind of search engine. In that case the page title will provide information to that engine, and enable your potential readers to (hopefully) select your page over other, similar alternatives. If all they see is "Untitled Document" (the default when no <title> is specified), that doesn't bode well for the user-friendliness of the rest of the page, and they probably wouldn't download it. I wouldn't.
End of lesson 1.
Material on this site is © Drew Whitworth and ACOM, 2002. Permission will usually be given to reproduce material from this site for non-commercial purposes, if credit is given. For enquiries, e-mail Drew at andrew [dot] whitworth [at] manchester [dot] ac [dot] uk.