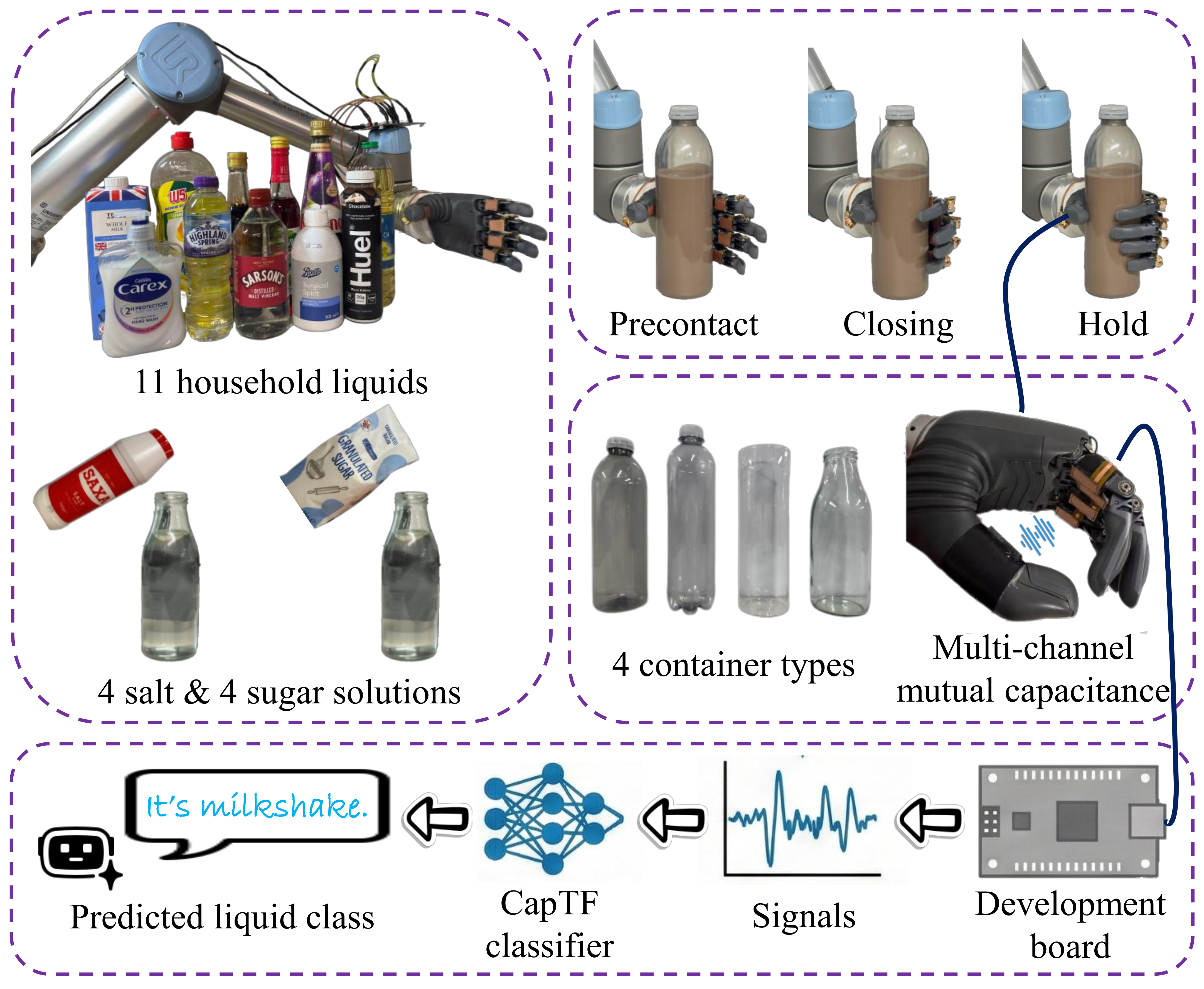
Robots and people often need to know what liquid is inside a sealed bottle before acting, but vision can fail for opaque or visually similar contents and continuous cameras may be undesirable in shared spaces. We present Touch2Know, a dexterous-hand sensing system that identifies liquid type and container type through the container wall during normal in-hand grasping, without opening the bottle. Touch2Know integrates five low-profile flex-PCB electrodes with guarded and shielded routing on a multi-finger hand, and measures multi-channel mutual capacitance to reduce common-mode drift and grounding sensitivity. An event-driven adaptive grasp controller stabilizes contact and limits over-compression across PET and glass bottles. For learning, we propose CapTF (Capacitive Temporal Fusion), a CNN–Transformer model that jointly predicts (i) liquid class and (ii) container type from 4-channel capacitive time series. We collect a dataset spanning 19 liquid classes and 4 container types over four days. CapTF achieves 95.17% liquid accuracy and 99.35% container accuracy under a balanced split, and 90% liquid accuracy on a Day-4 holdout test, outperforming LSTM, XGBoost, and a vanilla Transformer.
Overview
Figure 1. Touch2Know overview. A UR5-mounted dexterous hand performs an enveloping grasp and records 4-channel mutual-capacitance signals through sealed containers using five on-hand flex-PCB electrodes. The dataset covers 19 liquid classes and four container types over four days.
Method
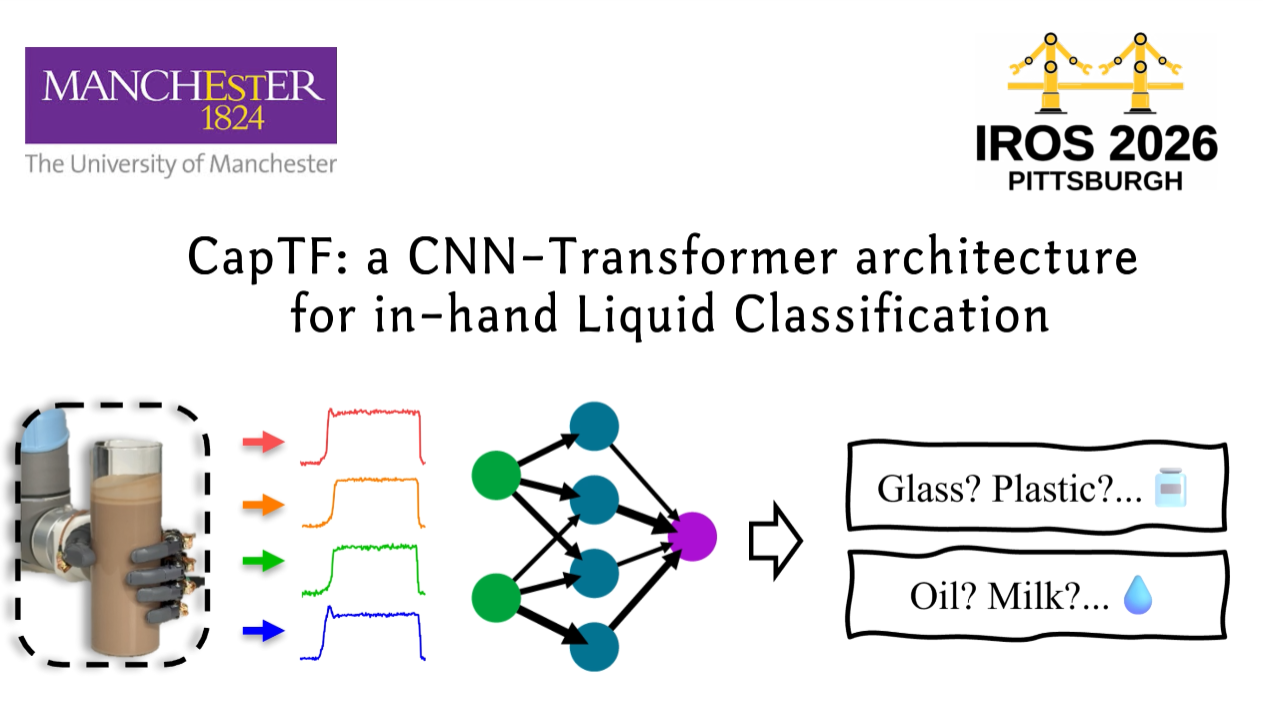
We measure mutual capacitance between a transmit electrode on the thumb and four receive electrodes on the other fingers during a stable enveloping grasp. Liquids with different relative permittivity and conductivity produce distinct multi-channel temporal signatures through the container wall. We propose CapTF, a multi-task CNN–Transformer that shares a backbone and branches into two classification heads for liquid and container type. Multi-task learning encourages the shared backbone to learn features less entangled with container-dependent offsets, improving liquid separability by ~3 pp over the single-task variant.
Figure 2. CapTF architecture. A multi-scale 1-D CNN embeds the 4-channel mutual-capacitance input; a Transformer encoder with learnable positional encoding captures temporal dependencies; multi-head pooling (mean + max + attention) produces a shared representation fed to two task-specific heads.
Results
CapTF outperforms all baselines under both balanced and cross-day evaluation. Delta (baseline-subtracted) features consistently outperform raw signals across all models, with per-trial baseline subtraction providing a +15 pp gain by removing environmental drift.
Model
Liq. Acc. (Balanced)
Liq. Acc. (Day-4)
Bot. Acc. (Balanced)
CapTF (Ours)
95.17%
90.00%
99.35%
CapTF-Liq (single-task)
92.11%
86.51%
—
LSTM
91.56%
83.68%
—
XGBoost
79.39%
77.37%
—
Vanilla Transformer
47.15%
45.00%
—
BibTeX
@inproceedings{deng2026touch2know,
title = {Touch2Know: Dexterous In-Hand Liquid Sensing
via Mutual-Capacitance Fingerprints},
author = {Deng, Ruixiang and Shangguan, Zhegong and
Hu, Yang and Bai, Haozheng and Li, Tingcheng
and Cangelosi, Angelo and Yang, Wuqiang},
booktitle = {IEEE/RSJ International Conference on
Intelligent Robots and Systems (IROS)},
year = {2026},
}