This worksheet is based on the third lecture of the Statistical Modelling in Stata course, created by Dr Mark Lunt and offered by the Centre for Epidemiology Versus Arthritis at the University of Manchester. The original Stata exercises and solutions are here translated into their R equivalents.
Refer to the original slides and Stata worksheets here.
Generating random samples
In this part of the practical, you are going to repeatedly generate random samples of varying size from a population with known mean and standard deviation. You can then see for yourselves how changing the sample size affects the variability of the sample mean. Obviously, this is not something that you would ever do in data analysis, but since all of the frequentist statistics we cover in this course are based on the concept of repeated sampling, it is useful to see some repeated samples.
Start a new R session.
In RStudio: go to Session > New Session, or clear the current working environment with Session > Clear Workspace….
In the original RGui, use Misc > Remove all objects.
Or in any console just type rm(list = ls()).
You could also create a new R Markdown document.
Create a variable called n that is equal to 5.
n <- 5Draw a sample vector, x, of length n from a standard normal distribution.
The standard normal is a normal distribution with mean 0 and standard deviation 1. The rnorm command draws random normal samples of a specified size:
x <- rnorm(n, mean = 0, sd = 1)In fact, in R the default arguments for rnorm are mean = 0 and sd = 1, so we can implicitly draw from the standard normal distribution with the more concise syntax:
x <- rnorm(n)Calculate the sample mean of the vector x.
mean(x)[1] -0.1882595Equivalently,
Repeat steps 1–4 ten times and record the results as the first column of a data frame called sample_means.
You can save yourself from mashing the same command in multiple times,
and in any case you should never enter data in manually if you can
avoid it. You can repeat a non-deterministic function using the
function replicate.
So to draw the ten samples, we could write
This will produce all 10 samples for you with a single command. You can see the samples with
samples [,1] [,2] [,3] [,4] [,5]
[1,] -0.08184662 0.7265851 -0.085368146 2.13554970 -1.7778863
[2,] -1.07716244 -0.6665179 -0.008910305 -0.45445896 -0.2897207
[3,] 1.52702530 2.0492276 0.142572002 1.56286324 1.4784068
[4,] 0.83924382 0.2470472 -0.419337611 -0.46827566 0.3561659
[5,] -0.52098947 1.9744478 -0.052082722 -0.02818759 -0.0630395
[,6] [,7] [,8] [,9] [,10]
[1,] 0.1271170 -1.7057359 1.2895573 -0.50005501 -0.7396136
[2,] -0.3173668 0.4636711 -0.9762716 -2.80833978 2.6879877
[3,] -1.7052411 0.8033420 1.5732223 -1.37664987 -0.3524730
[4,] 1.5858366 -0.9401680 -0.6877889 -0.03724965 2.0973991
[5,] 0.5246914 -1.3448204 -1.5175702 0.30810877 -0.6745231You can now calculate the mean of each sample and save it in a new
data frame as a column called n_5 with the command:
sample_means <- data.frame(n_5 = apply(samples, 2, mean))The apply function tells R to apply the function mean to the columns
(dimension 2, hence the 2) of the matrix samples.
Now generate a further ten samples, but each of size 25. Store the means of these samples.
Add a third column to your data frame corresponding to the means of ten vectors of sample size n = 100.
As before:
The resulting data frame might look something like:
sample_means n_5 n_25 n_100
1 0.13725412 -0.095078352 -2.773196e-01
2 0.86615796 0.144451803 -6.486005e-02
3 -0.08462536 -0.096347255 5.932334e-02
4 0.54949815 0.146847895 4.167297e-02
5 -0.05921475 -0.064592533 3.212846e-02
6 0.04300741 -0.229768636 5.411997e-02
7 -0.54474224 -0.007472736 -3.114432e-05
8 -0.06377021 -0.364740063 -1.437333e-01
9 -0.88283711 0.074958874 9.010720e-02
10 0.60375541 0.071105960 -2.034298e-01Now calculate the mean and standard deviation of the values in each column.
Everything is in a data frame, so finding summary statistics for each column is straightforward. For each column, we can call something like
But to save time typing that out three times, we can calculate for all the columns at once:
apply(sample_means, MARGIN = 2, FUN = mean) n_5 n_25 n_100
0.05644834 -0.04206350 -0.04120220 apply(sample_means, MARGIN = 2, FUN = sd) n_5 n_25 n_100
0.5266669 0.1645843 0.1262784 A shorthand for calculating the means is:
colMeans(sample_means) n_5 n_25 n_100
0.05644834 -0.04206350 -0.04120220 and while there isn’t a function called colVars or colSDs, you can compute the variance–covariance matrix and read the numbers off the diagonal:
cov(sample_means) n_5 n_25 n_100
n_5 0.27737806 0.024742875 -0.027318808
n_25 0.02474288 0.027087978 0.003363918
n_100 -0.02731881 0.003363918 0.015946240 n_5 n_25 n_100
0.5266669 0.1645843 0.1262784 If you prefer dplyr:
library(dplyr)
summarise_all(sample_means, mean) n_5 n_25 n_100
1 0.05644834 -0.0420635 -0.0412022summarise_all(sample_means, sd) n_5 n_25 n_100
1 0.5266669 0.1645843 0.1262784And finally data.table:
library(data.table)
setDT(sample_means)
sample_means[, .(n = names(sample_means),
mean = sapply(.SD, mean),
sd = sapply(.SD, sd))] n mean sd
1: n_5 0.05644834 0.5266669
2: n_25 -0.04206350 0.1645843
3: n_100 -0.04120220 0.1262784Means
This section is bookwork and does not require R or Stata. See the Stata solution for the answers
If the standard deviation of the original distribution is \(\sigma\), then the standard error of the sample mean is \(\sigma/\sqrt{n}\), where \(n\) is the sample size.
- If the standard deviation of measured heights is 9.31 cm, what will be the standard error of the mean in:
- a sample of size 49?
- a sample of size 100?
- Imagine we only had data on a sample of size 100, where the sample mean was 166.2 cm and the sample standard deviation was 10.1 cm.
- Calculate the standard error for this sample mean (using the sample standard deviation as an estimate of the population standard deviation).
- Calculate the interval ranging 1.96 standard errors either side of the sample mean.
- Imagine we only had data on a sample size of 36 where the sample mean height was 163.5 cm and the standard deviation was 10.5cm.
- Within what interval would you expect about 95% of heights from this population to lie (the reference range)?
- Calculate the 95% confidence interval for the sample mean.
- Figure 1 is a histogram of measured weight in a sample of 100 individuals.
- Would it be better to use the mean and standard deviation or the median and interquartile range to summarise these data?
- If the mean of the data is 69.69 kg with a standard deviation of 12.76 kg, calculate a 95% confidence interval for the mean.
- Why is it not sensible to calculate a 95% reference range for these data?
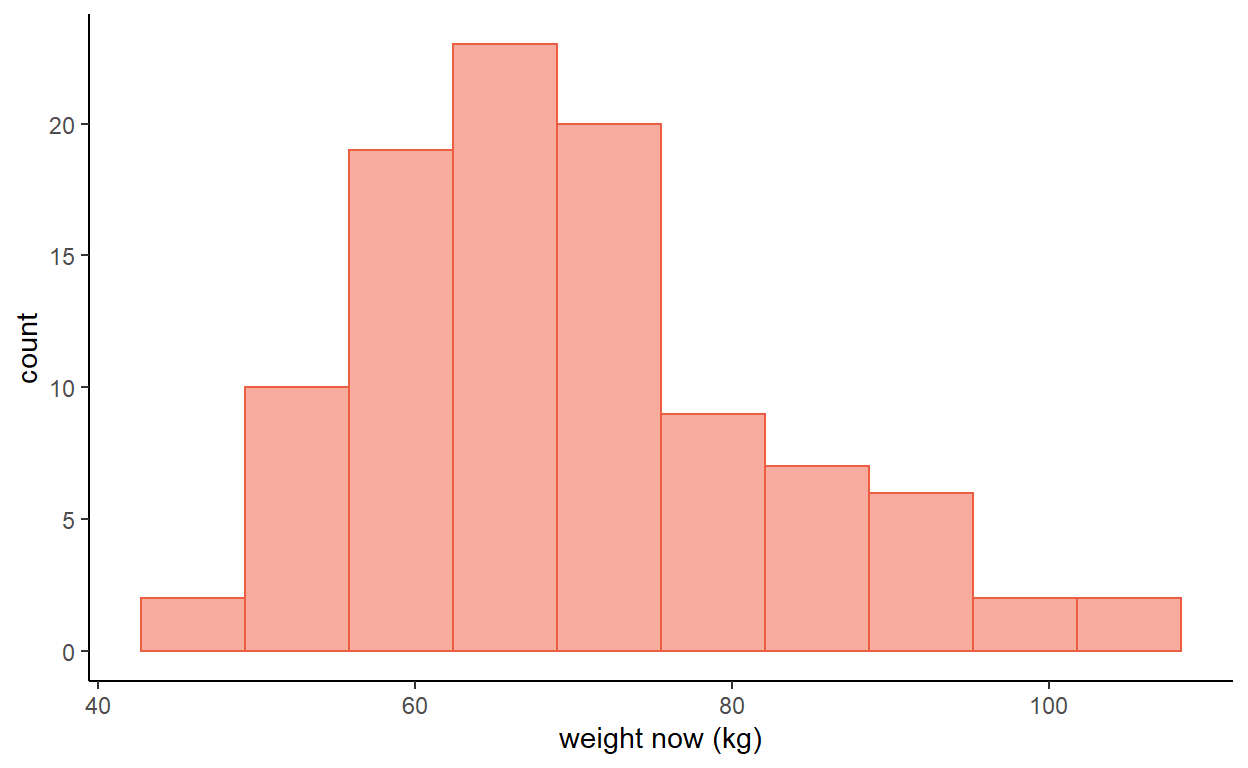
Figure 1: Weights in a random sample of 100 women
Proportions
This section is bookwork and does not require R or Stata. See the Stata solution for the answers
Again using our height and weight dataset of 412 individuals, 234 (56.8%) are women and 178 (43.2%) are men.
If we take a number of smaller samples from this population, the proportion of women will vary, although they will tend to be scattered around 57%. Figure 2 represents 50 samples, each of size 40.
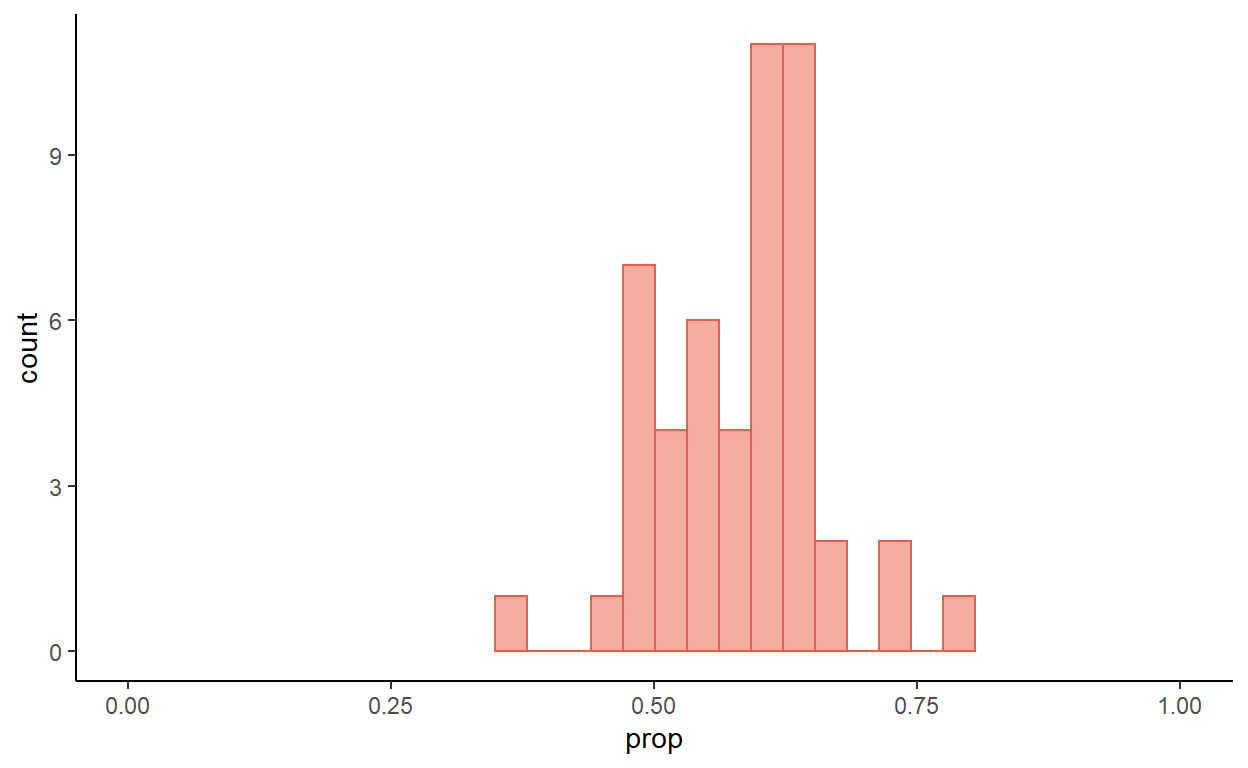
Figure 2: Proportion of women in 50 samples of size 40
What would you expect to happen if the sample sizes were bigger, say \(n=100\)?
In a sample of 40 individuals from a larger population, 25 are women. Calculate a 95% confidence interval for the proportion of women in the population.
Note. When sample sizes are small, the use of standard errors and the normal distribution does not work well for proportions. This is only really a problem if \(p\) (or \((1-p)\)) is less than \(5/n\) (i.e. there are fewer than 5 subjects in one of the groups).
- From a random sample of 80 women who attend a general practice, 18 report a previous history of asthma.
- Estimate the proportion of women in this population with a previous history of asthma, along with a 95% confidence interval for this proportion.
- Is the use of the normal distribution valid in this instance?
- In a random sample of 150 Manchester adults it was found that 58 received or needed to receive treatment for defective vision.
Estimate:
- the proportion of adults in Manchester who receive or need to receive treatment for defective vision,
- a 95% confidence interval for this proportion.
Confidence intervals in R
Download the bpwide.csv dataset.
Load the blood pressure data in its wide form into R with the command
bpwide <- read.csv('bpwide.csv')This is fictional data concerning blood pressure before and after a particular intervention.
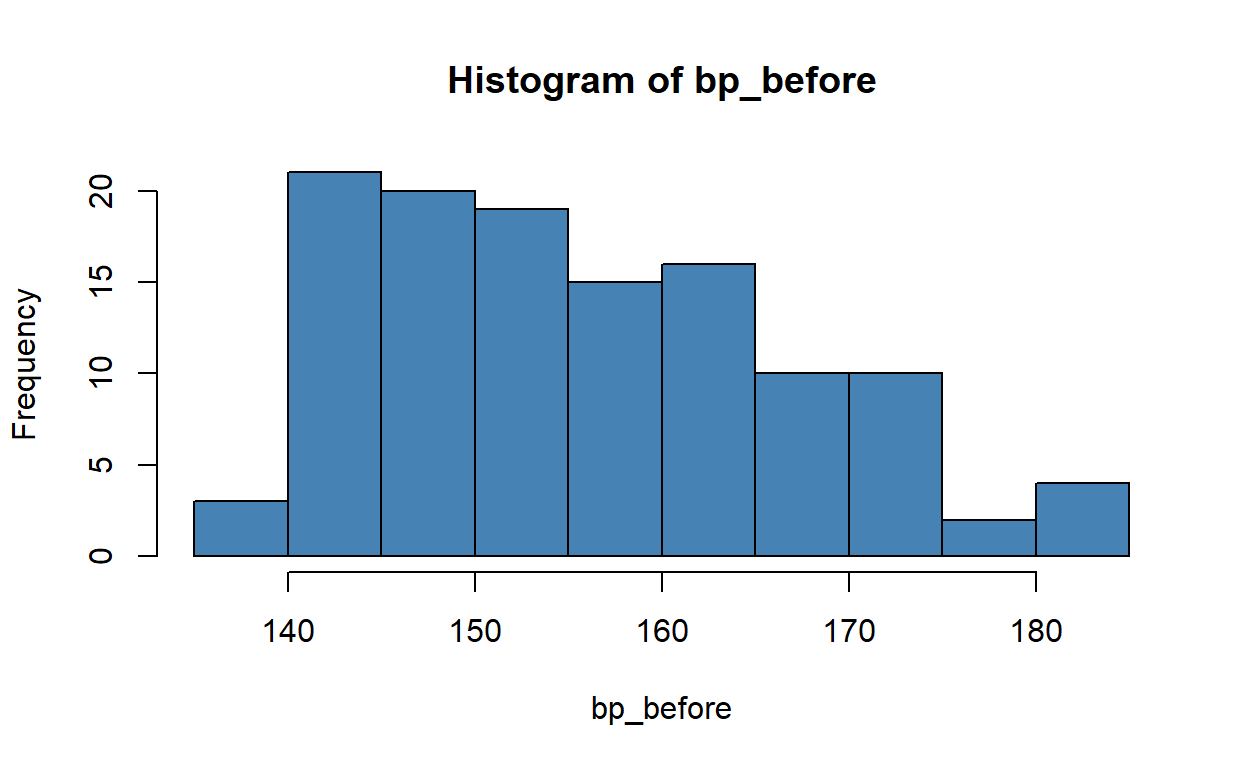
Use an appropriate visualisation to whether or not the variable bp_before is skewed. What do you think?
The original Stata solution calls for a histogram, for example:
However, a kernel density plot smooths out the histogram and may make it easier to visualise the distribution.
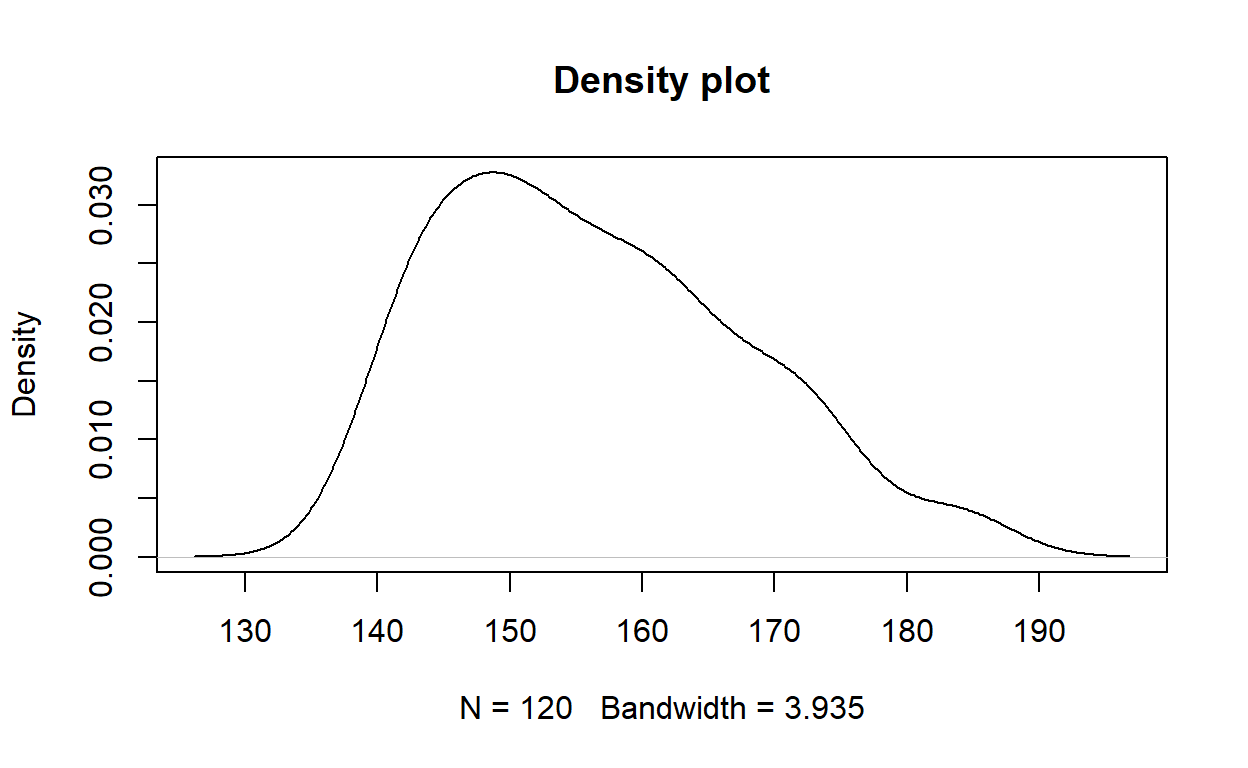
There is a slight positive (right) skew.
Create a new variable to measure the change in blood pressure.
You can create a standalone variable:
bp_diff <- with(bpwide, bp_after - bp_before)Or, since it is of the same length as bp_after and bp_before, you can store it as a new column in the bpwide data frame.
bpwide <- transform(bpwide, bp_diff = bp_after - bp_before)What is the mean change in blood pressure?
Compute a confidence interval for the change in blood pressure.
As we are looking at a difference in means, we compare the sample blood pressure difference to a Student’s t distribution with \(n - 1\) degrees of freedom, where \(n\) is the number of patients.
By hand: the formula for a two-sided \((1-\alpha)\) confidence interval for a sample of size \(n\) is \[Pr\left(\bar{X}_n - t_{n-1}(\alpha/2) \frac{S_n}{\sqrt n} < \mu < \bar{X} + t_{n-1}(\alpha/2) \frac{S_n}{\sqrt n}\right) = \alpha \]
In R, the q family of functions returns quantiles of distributions (just as we have seen the r family draws random samples from those distributions).
So qnorm finds the quantiles of the normal distribution, qt the quantiles of the Student’s t-distribution, and so on.
We can use it to retrieve the 2.5% and 97.5% quantiles of the t distribution with \(n-1\) degrees of freedom and then plug them into the above formula, like so:
n <- length(bp_diff) # or nrow(bpwide)
mean(bp_diff) + qt(c(.025, .975), df = n - 1) * sd(bp_diff) / sqrt(n)[1] -8.112776 -2.070557Or, using the built-in t.test function we get the same result:
Paired t-test
data: bp_before and bp_after
t = 3.3372, df = 119, p-value = 0.00113
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
2.070557 8.112776
sample estimates:
mean of the differences
5.091667 As the 95% confidence interval does not contain zero, we may reject the hypothesis that, on average, there was no change in blood pressure.
Notice that the paired t.test did not require us to calculate bp_diff.
But we can pass the same to t.test for a one-sample test and it will compute exactly the same test statistic, because testing whether two variables are equal is the same thing as testing whether their paired difference is zero.
t.test(bp_diff)
One Sample t-test
data: bp_diff
t = -3.3372, df = 119, p-value = 0.00113
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-8.112776 -2.070557
sample estimates:
mean of x
-5.091667 Look at the histogram of changes in blood pressure using the command hist.
hist(bp_diff, col = 'steelblue')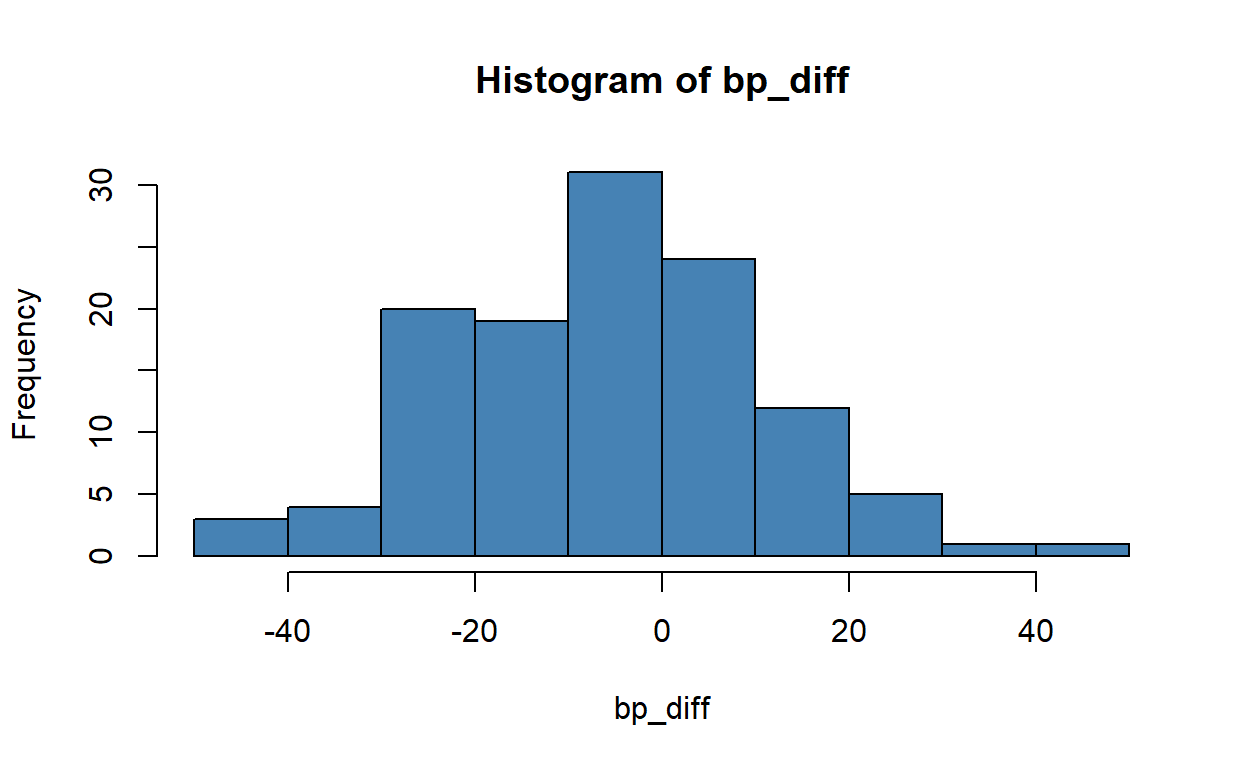
You could also try a kernel density plot, or even an old-fashioned stem and leaf diagram:
stem(bp_diff)
The decimal point is 1 digit(s) to the right of the |
-4 | 55
-4 | 2
-3 |
-3 | 3000
-2 | 99977776
-2 | 443322222100
-1 | 9988666555
-1 | 422211000
-0 | 9998877776655
-0 | 43333333222111
0 | 000022222333
0 | 566777788899
1 | 00001234444
1 | 55599
2 | 1
2 | 5679
3 |
3 | 6
4 | 1Does this confirm your answer to the previous question?
Create a new variable to indicate whether blood pressure went up or down in a given subject.
down <- with(bpwide, bp_after < bp_before)Use the table command to see how many subjects showed a decrease in blood pressure.
table(down)down
FALSE TRUE
47 73 To get proportions, you can use prop.table, like so:
prop.table(table(down))down
FALSE TRUE
0.3916667 0.6083333 But it is just as quick to take the mean of the binary indicators (as TRUE == 1 and FALSE == 0):
Create a confidence interval for the proportion of subjects showing a decrease in blood pressure.
Note. The point of this is to create a confidence interval around a proportion. Making inference about dichotomised categorical variables is rarely a good idea, although clinically meaningful classifications can be very useful in describing your data. The problem with inference is that you lose power by discarding a lot of information, and you can reverse the effect: if most people show a slight decrease in blood pressure, but a few show a large increase, the mean change may be greater than 0 even though most subjects show a decrease.
Nonetheless, given that the purpose of the exercise is to create a binomial confidence interval, then we have:
binom.test(sum(down), n)
Exact binomial test
data: sum(down) and n
number of successes = 73, number of trials = 120, p-value =
0.02208
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.5150437 0.6961433
sample estimates:
probability of success
0.6083333